Part1:JVM内存结构
JVM定义了若干个程序执行期间使用的数据区域。这个区域里的一些数据在JVM启动的时候创建,在JVM退出的时候销毁。而其他的数据依赖于每一个线程,在线程创建时创建,在线程退出时销毁
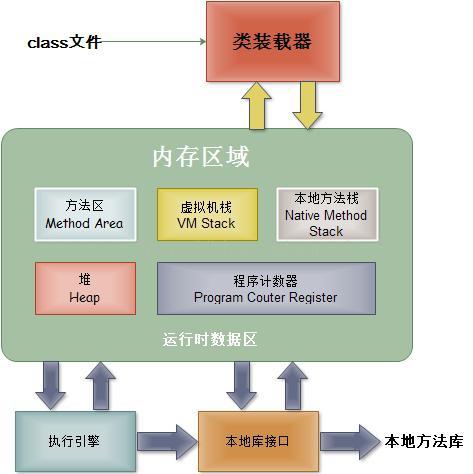
可以把JVM内存结构为2个部分:
线程私有部分:
1. Program Counter Register(程序计数器):一块较小的内存空间, 作用是当前线程所执行字节码的行号指示器(类似于传统CPU模型中的PC), PC在每次指令执行后自增, 维护下一个将要执行指令的地址. 在JVM模型中, 字节码解释器就是通过改变PC值来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖PC完成(仅限于Java方法, Native方法该计数器值为undefined).
PS:通俗来讲就是每个线程都有一个程序计数器,跟踪代码运行到哪个位置了
2. Java Stack(虚拟机栈): 虚拟机栈描述的是Java方法执行的内存模型: 每个方法被执行时会创建一个栈帧(Stack Frame)用于存储局部变量表、操作数栈、动态链接、方法出口等信息. 每个方法被调用至返回的过程, 就对应着一个栈帧在虚拟机栈中从入栈到出栈的过程(VM提供了-Xss来指定线程的最大栈空间, 该参数也直接决定了函数调用的最大深度).
PS:就是线程执行方法时存放每个方法的局部变量和操作等,方法的执行过程就是入栈和出栈的过程
3. Native Method Stack(本地方法栈):与Java Stack作用类似, 区别是Java Stack为执行Java方法服务, 而本地方法栈则为Native方法服务, 如果一个VM实现使用C-linkage模型来支持Native调用, 那么该栈将会是一个C栈
PS:原理和Java Stack一致吗,区别是只有执行JVM的native方法,使用的是Native Method Stack的内存
线程共享部分:
1. Heap(Java堆):几乎所有对象实例和数组都要在堆上分配(栈上分配、标量替换除外), 因此是VM管理的最大一块内存, 也是垃圾收集器的主要活动区域. 由于现代VM采用分代收集算法, 因此Java堆从GC的角度还可以细分为: 新生代(Eden区、From Survivor区和To Survivor区)和老年代; 而从内存分配的角度来看, 线程共享的Java堆还还可以划分出多个线程私有的分配缓冲区(TLAB). 而进一步划分的目的是为了更好地回收内存和更快地分配内存.
PS:可以理解为存放每个对象和数组的区域
2. Method Area(方法区):即我们常说的永久代(Permanent Generation), 用于存储被JVM加载的类信息、常量、静态变量、即时编译器编译后的代码等数据. HotSpot VM把GC分代收集扩展至方法区, 即使用Java堆的永久代来实现方法区, 这样HotSpot的垃圾收集器就可以像管理Java堆一样管理这部分内存, 而不必为方法区开发专门的内存管理器(永久带的内存回收的主要目标是针对常量池的回收和类型的卸载, 因此收益一般很小)
PS:可以理解为存放类的一些常量,静态变量的区域
线程私有的内存区域的生命周期随着线程的创建而创建,随着线程的消亡而消亡,随便不需要进行垃圾回收,而线程共享(堆和方法区)的内存区域随虚拟机的启动/关闭而创建/销毁.所以要进行垃圾回收,具体的垃圾回收原理在下一节中会有讲解(参考:)
Part2:JVM类加载机制
概述:JVM要想执行class文件,需要经过类加载器加载,将文件载入虚拟机的方法区内,根据类文件的格式相应的存放数据。在需要产生对象时,从方法区中获取对应的类信息,在堆中建立对象。
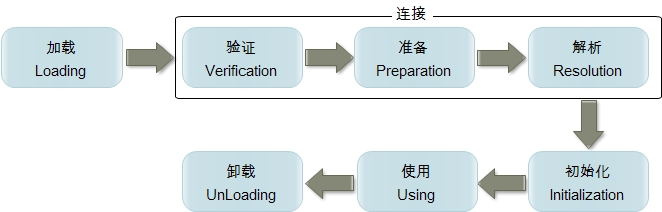
加载过程(如上图)
1.装载:查找和导入class文件;
2.连接:
(1)检查:检查载入的class文件数据的正确性;
(2)准备: 准备阶段是为类的静态变量分配内存并将其初始化为默认值,这些内存都将在方法区中进行分配。准备阶段不分配类中的实例变量的内存,实例变量将会在对象实例化时随着对象一起分配在Java堆中。
(3)解析:将符号引用转换成直接引用(这一步是可选的)
3.初始化:类初始化是类加载过程的最后一步,前面的类加载过程,除了在加载阶段用户应用程序可以通过自定义类加载器参与之外,其余动作完全由虚拟机主导和控制。到了初始化阶段,才真正开始执行类中定义的Java程序代码。
其中,加载、验证、准备、初始化和卸载这五个阶段的顺序是确定的,类的加载过程必须按照这种顺序按部就班的“开始”(仅仅指的是开始,而非执行或者结束,因为这些阶段通常都是互相交叉的混合进行,通常会在一个阶段执行的过程中调用或者激活另一个阶段),而解析阶段则不一定(它在某些情况下可以在初始化阶段之后再开始,这是为了支持Java语言的运行时绑定。
类加载的几个时机
1.创建类的实例
2.访问类的静态变量
3.访问类的静态方法
4.反射如(Class.forName("my.xyz.Test") ClassRoader)
5.当初始化一个类时,发现其父类还未初始化,则先出发父类的初始化
6.虚拟机启动时,定义了main()方法的那个类先初始化
双亲委托模式
当类加载器需要加载类的时候,先请示其Parent(即上一层加载器)在其搜索路径载入,如果找不到,才在自己的搜索路径搜索该类。这样的顺序其实就是加载器层次上自顶而下的搜索,因为加载器必须保证基础类的加载。之所以是这种机制,还有一个安全上的考虑:如果某人将一个恶意重写的基础类加载到jvm,委托模型机制会搜索其父类加载器,发现已经存在就不会加载。
1.Bootstrap class loader (引导类加载器)
负责加载Java核心类库。在jre\lib目录下,包括rt.jar(Java基础类库),这些
都是Java的核心类库。而且这个加载器是由C语言编写的,所以在Java程序中是获取
不到的。
2.Extension class loader(扩展类加载器)
负责加载Java平台下扩展功能的jar包,这些jar包在jre\lib\ext目录下。这个加载
器由Java语言编写的。
3.System class loader(系统类加载器)
负责加载classpath目录下的所有类库,classpath目录下的class文件一般
是我们自己写的java文件编译后的。而这个加载器是由Java语言写的
委托机制的意义 — 防止内存中出现多份同样的字节码
-
比如两个类A和类B都要加载System类:
- 如果不用委托而是自己加载自己的,那么类A就会加载一份System字节码,然后类B又会加载一份System字节码,这样内存中就出现了两份System字节码。
- 如果使用委托机制,会递归的向父类查找,也就是首选用Bootstrap尝试加载,如果找不到再向下。这里的System就能在Bootstrap中找到然后加载,如果此时类B也要加载System,也从Bootstrap开始,此时Bootstrap发现已经加载过了System那么直接返回内存中的System即可而不需要重新加载,这样内存中就只有一份System的字节码了。
lass SingleTon { private static SingleTon singleTon = new SingleTon(); public static int count1; public static int count2 = 0; private SingleTon() { count1++; count2++; } public static SingleTon getInstance() { return singleTon; } } public class Test { public static void main(String[] args) { SingleTon singleTon = SingleTon.getInstance(); System.out.println("count1=" + singleTon.count1); System.out.println("count2=" + singleTon.count2); } } 最终输出结果是 :
count1=1
count2=0我们从类的加载机制分析: 1:执行main方法的时候SingleTon.getInstance()方法会进行类加载,在类加载准备阶段,jvm会为静态变量分配内存并初始化默认值(上面代码:singleTon = null ;count1 =0 ; count2=0;) 2:准备阶段过后,进入初始化阶段,常量池内的符号引用替换为直接引用的过程(上诉代码:给静态变量赋值 singleTon=new SingleTon(),执行构造方法,count1=1;count2=1;继续给静态变量赋值:count1不变,count2=0)